All leaked interview problems are collected from Internet.
505. The Maze II
There is a ball in a maze with empty spaces and walls. The ball can go through empty spaces by rolling up, down, left or right, but it won't stop rolling until hitting a wall. When the ball stops, it could choose the next direction.
Given the ball's start position, the destination and the maze, find the shortest distance for the ball to stop at the destination. The distance is defined by the number of empty spaces traveled by the ball from the start position (excluded) to the destination (included). If the ball cannot stop at the destination, return -1.
The maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The start and destination coordinates are represented by row and column indexes.
Example 1
Input 1: a maze represented by a 2D array
0 0 1 0 0
0 0 0 0 0
0 0 0 1 0
1 1 0 1 1
0 0 0 0 0
Input 2: start coordinate (rowStart, colStart) = (0, 4)
Input 3: destination coordinate (rowDest, colDest) = (4, 4)
Output: 12
Explanation: One shortest way is : left -> down -> left -> down -> right -> down -> right.
The total distance is 1 + 1 + 3 + 1 + 2 + 2 + 2 = 12.
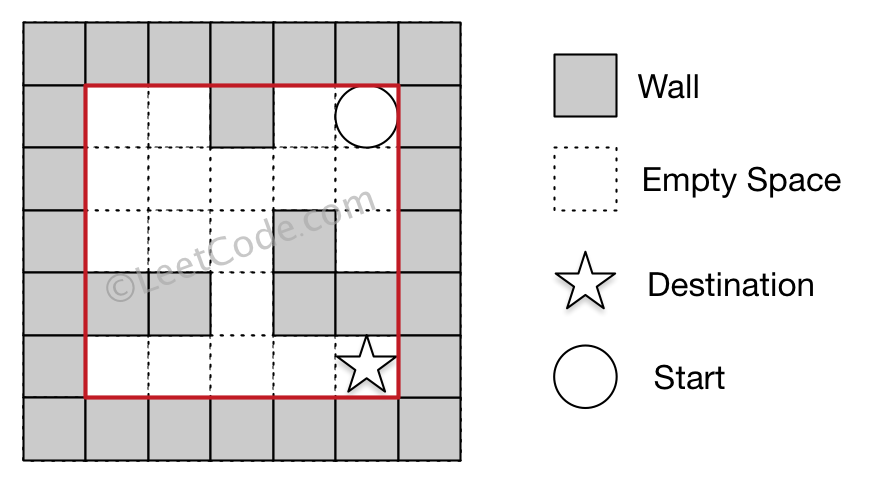
Example 2
Input 1: a maze represented by a 2D array 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 1 1 0 0 0 0 0 Input 2: start coordinate (rowStart, colStart) = (0, 4) Input 3: destination coordinate (rowDest, colDest) = (3, 2) Output: -1 Explanation: There is no way for the ball to stop at the destination.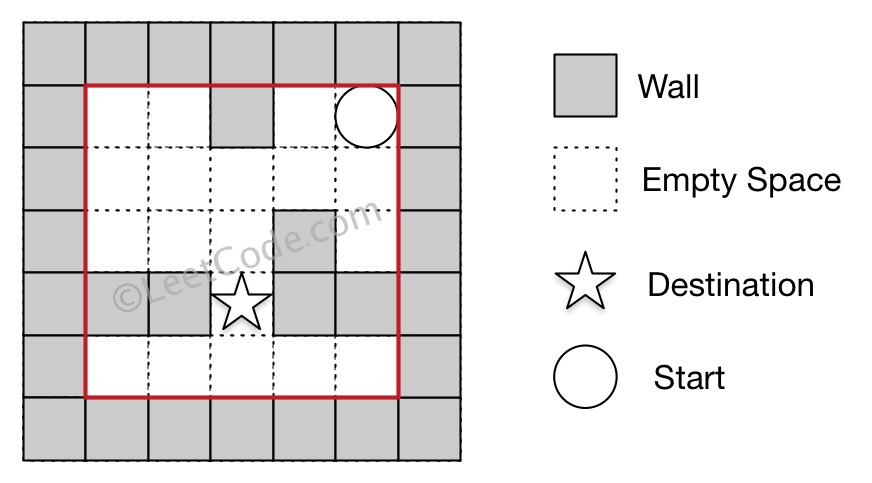
Note:
- There is only one ball and one destination in the maze.
- Both the ball and the destination exist on an empty space, and they will not be at the same position initially.
- The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls.
- The maze contains at least 2 empty spaces, and both the width and height of the maze won't exceed 100.
Solution
Approach #1 Depth First Search [Accepted]
We can view the given search space in the form of a tree. The root node of the tree represents the starting position. Four different routes are possible from each position i.e. left, right, up or down. These four options can be represented by 4 branches of each node in the given tree. Thus, the new node reached from the root traversing over the branch represents the new position occupied by the ball after choosing the corresponding direction of travel.
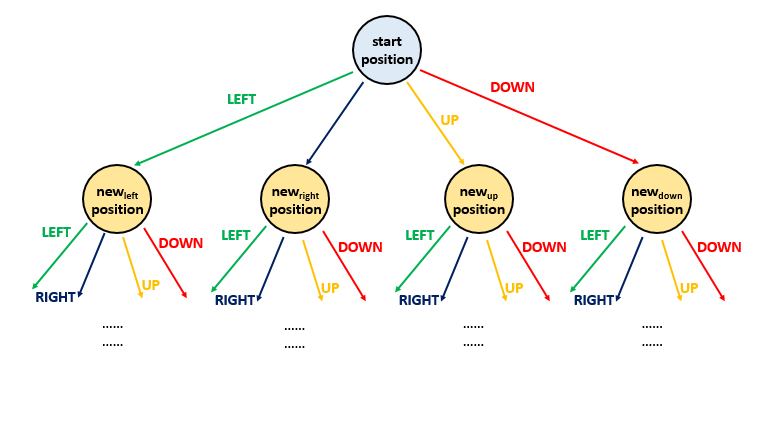
In order to do this traversal, one of the simplest schemes is to undergo depth first search. We make use of a recursive function dfs for this. From every current position, we try to go as deep as possible into the levels of a tree taking a particular branch traversal direction as possible. When one of the deepest levels is exhausted, we continue the process by reaching the next deepest levels of the tree. In order to travel in the various directions from the current position, we make use of a array. is an array with 4 elements, where each of the elements represents a single step of a one-dimensional movement. For travelling in a particular direction, we keep on adding the appropriate element in the current position till the ball hits a boundary or a wall.
We start with the given position, and try to explore these directions represented by the array one by one. For every element of the chosen for the current travelling direction, we determine how far can the ball travel in this direction prior to hitting a wall or a boundary. We keep a track of the number of steps using variable.
Apart from this, we also make use of a 2-D array. represents the minimum number of steps required to reach the positon starting from the position. This array is initialized with largest integer values in the beginning.
When we reach any position next to a boundary or a wall during the traversal in a particular direction, as discussed earlier, we keep a track of the number of steps taken in the last direction in variable. Suppose, we reach the position starting from the last position . Now, for this position, we need to determine the minimum number of steps taken to reach this position starting from the position. For this, we check if the current path takes lesser steps to reach than any other previous path taken to reach the same position i.e. we check if is lesser than . If not, we continue the process of traversal from the position in the next direction.
If is lesser than , we can reach the position from the current route in lesser number of steps. Thus, we need to update the value of as . Further, now we need to try to reach the destination, , from the end position , since this could lead to a shorter path to . Thus, we again call the same function dfs but with the position acting as the current position.
After this, we try to explore the routes possible by choosing all the other directions of travel from the current position as well.
At the end, the entry in distance array corresponding to the destination, 's coordinates gives the required minimum distance to reach the destination. If the destination can't be reached, the corresponding entry will contain .
The following animation depicts the process.
!?!../Documents/505_Maze2_DFS.json:1000,563!?!
Complexity Analysis
-
Time complexity : . Complete traversal of maze will be done in the worst case. Here, and refers to the number of rows and columns of the maze. Further, for every current node chosen, we can travel upto a maximum depth of in any direction.
-
Space complexity : . array of size is used.
Approach #2 Using Breadth First Search [Accepted]
Algorithm
Instead of making use of Depth First Search for exploring the search space, we can make use of Breadth First Search as well. In this, instead of exploring the search space on a depth basis, we traverse the search space(tree) on a level by level basis i.e. we explore all the new positions that can be reached starting from the current position first, before moving onto the next positions that can be reached from these new positions.
In order to make a traversal in any direction, we again make use of array as in the DFS approach. Again, whenever we make a traversal in any direction, we keep a track of the number of steps taken while moving in this direction in variable as done in the last approach. We also make use of array initialized with very large values in the beginning. again represents the minimum number of steps required to reach the position from the position.
This approach differs from the last approach only in the way the search space is explored. In order to reach the new positions in a Breadth First Search order, we make use of a , which contains the new positions to be explored in the future. We start from the current position , try to traverse in a particular direction, obtain the corresponding for that direction, reaching an end position of just near the boundary or a wall. If the position can be reached in a lesser number of steps from the current route than any other previous route checked, indicated by , we need to update as .
After this, we add the new position obtained, to the back of a , so that the various paths possible from this new position will be explored later on when all the directions possible from the current position have been explored. After exploring all the directions from the current position, we remove an element from the front of the and continue checking the routes possible through all the directions now taking the new position(obtained from the ) as the current position.
Again, the entry in distance array corresponding to the destination, 's coordinates gives the required minimum distance to reach the destination. If the destination can't be reached, the corresponding entry will contain .
Complexity Analysis
-
Time complexity : . Time complexity : . Complete traversal of maze will be done in the worst case. Here, and refers to the number of rows and columns of the maze. Further, for every current node chosen, we can travel upto a maximum depth of in any direction.
-
Space complexity : . size can grow upto in the worst case.
Approach #3 Using Dijkstra Algorithm [Accepted]
Algorithm
Before we look into this approach, we take a quick overview of Dijkstra's Algorithm.
Dijkstra's Algorithm is a very famous graph algorithm, which is used to find the shortest path from any node to any node in the given weighted graph(the edges of the graph represent the distance between the nodes).
The algorithm consists of the following steps:
-
Assign a tentative distance value to every node: set it to zero for our node and to infinity for all other nodes.
-
Set the node as node. Mark it as visited.
-
For the node, consider all of its neighbors and calculate their tentative distances. Compare the newly calculated tentative distance to the current assigned value and assign the smaller one to all the neighbors. For example, if the current node A is marked with a distance of 6, and the edge connecting it with a neighbor B has length 2, then the distance to B (through A) will be 6 + 2 = 8. If B was previously marked with a distance greater than 8 then change it to 8. Otherwise, keep the current value.
-
When we are done considering all of the neighbors of the current node, mark the node as visited. A visited node will never be checked again.
-
If the node has been marked visited or if the smallest tentative distance among all the nodes left is infinity(indicating that the can't be reached), then stop. The algorithm has finished.
-
Otherwise, select the unvisited node that is marked with the smallest tentative distance, set it as the new node, and go back to step 3.
The working of this algorithm can be understood by taking two simple examples. Consider the first set of nodes as shown below.
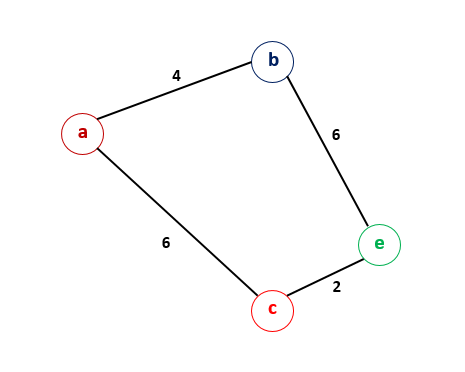
Suppose that the node is at a shorter distance from the node as compared to , but the distance from to the node, , is shorter through the node itself. In this case, we need to check if the Dijkstra's algorithm works correctly, since the node is considered first while selecting the nodes being at a shorter distance from . Let's look into this.
-
Firstly, we choose as the node, mark it as visited and update the and values. Here, represents the distance of node from the node.
-
Since , is chosen as the next node for calculating the distances. We mark as visited. Now, we update the value as .
-
Now, is obviously the next node to be chosen as per the conditions of the assumptions taken above. (For path to through to be shorter than path to through , . From , we determine the distance to node . Since is shorter than the previous value of , we update with the correct shorter value.
-
We choose as the current node. No other distances need to be updated. Thus, we mark as visited. now gives the required shortest distance.
The above example proves that even if a locally closer node is chosen as the current node first, the ultimate shortest distance to any node is calculated correctly.
Let's take another example to demonstrate that the visited node needs not be chosen again as the current node.
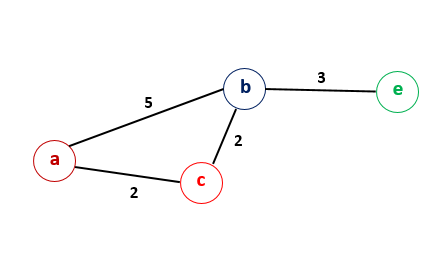
Suppose is the node and is the node. Now, suppose we visit first and mark it as visited, but later on we find that another path exists through to , which makes the shorter than the previous value. But, because of this, we need to consider as the current node again, since it would affect the value of . But, if we observe closely, such a situation would never occur, because for to be lesser than , in the first place. Thus, would never be marked before , which contradicts the first assumption. This proves that the node needs not be chosen as the current node again.
The given problem is also a shortest distance finding problem with a slightly different set of rules. Thus, we can make use of Dijkstra's Algorithm to determine the minimum number of steps to reach the destination.
The methodology remains the same as the DFS or BFS Approach discussed above, except the order in which the current positions are chosen. We again make use of a array to keep a track of the minimum number of steps needed to reach every position from the position. At every step, we choose a position which hasn't been marked as visited and which is at the shortest distance from the position to be the current position. We mark this position as visited so that we don't consider this position as the current position again.
From the current position, we determine the number of steps required to reach all the positions possible travelling from the current position(in all the four directions possible till hitting a wall/boundary). If it is possible to reach any position through the current route with a lesser number of steps than the earlier routes considered, we update the corresponding entry. We continue the same process for the other directions as well for the current position.
In order to determine the current node, we make use of minDistance function, in which we traverse over the whole array and find out an unvisited node at the shortest distance from the node.
At the end, the entry in array corresponding to the position gives the required minimum number of steps. If the destination can't be reached, the corresponding entry will contain .
Complexity Analysis
-
Time complexity : . Complete traversal of maze will be done in the worst case and function
minDistancetakes time. -
Space complexity : . array of size is used.
Approach #4 Using Dijkstra Algorithm and Priority Queue[Accepted]
Algorithm
In the last approach, in order to choose the current node, we traversed over the whole array and found out an unvisited node at the shortest distance from the node. Rather than doing this, we can do the same task much efficiently by making use of a Priority Queue, . This priority queue is implemented internally in the form of a heap. The criteria used for heapifying is that the node which is unvisited and at the smallest distance from the node, is always present on the top of the heap. Thus, the node to be chosen as the current node, is always present at the front of the .
For every current node, we again try to traverse in all the possible directions. We determine the minimum number of steps(till now) required to reach all the end points possible from the current node. If any such end point can be reached in a lesser number of steps through the current path than the paths previously considered, we need to update its entry.
Further, we add an entry corresponding to this node in the , since its entry has been updated and we need to consider this node as the competitors for the next current node choice. Thus, the process remains the same as the last approach, except the way in which the pick out the current node(which is the unvisited node at the shortest distance from the node).
Complexity Analysis
-
Time complexity : . Complete traversal of maze will be done in the worst case giving a factor of . Further,
pollmethod is a combination of heapifying() and removing the top element() from the priority queue, and it takes time for elements. In the current case,pollintroduces a factor of . -
Space complexity : . array of size is used and size can grow upto in worst case.
Analysis written by: @vinod23