All leaked interview problems are collected from Internet.
535. Encode and Decode TinyURL
Note: This is a companion problem to the System Design problem: Design TinyURL.
TinyURL is a URL shortening service where you enter a URL such as https://leetcode.com/problems/design-tinyurl and it returns a short URL such as http://tinyurl.com/4e9iAk.
Design the encode and decode methods for the TinyURL service. There is no restriction on how your encode/decode algorithm should work. You just need to ensure that a URL can be encoded to a tiny URL and the tiny URL can be decoded to the original URL.
Solution
Approach #1 Using Simple Counter[Accepted]
In order to encode the URL, we make use of a counter(), which is incremented for every new URL encountered. We put the URL along with its encoded count() in a HashMap. This way we can retrieve it later at the time of decoding easily.
Performance Analysis
-
The range of URLs that can be decoded is limited by the range of .
-
If excessively large number of URLs have to be encoded, after the range of is exceeded, integer overflow could lead to overwriting the previous URLs' encodings, leading to the performance degradation.
-
The length of the URL isn't necessarily shorter than the incoming . It is only dependent on the relative order in which the URLs are encoded.
-
One problem with this method is that it is very easy to predict the next code generated, since the pattern can be detected by generating a few encoded URLs.
Approach #2 Variable-length Encoding[Accepted]
Algorithm
In this case, we make use of variable length encoding to encode the given URLs. For every , we choose a variable codelength for the input URL, which can be any length between 0 and 61. Further, instead of using only numbers as the Base System for encoding the URLSs, we make use of a set of integers and alphabets to be used for encoding.
Performance Analysis
-
The number of URLs that can be encoded is, again, dependent on the range of , since, the same will be generated after overflow of integers.
-
The length of the encoded URLs isn't necessarily short, but is to some extent dependent on the order in which the incoming 's are encountered. For example, the codes generated will have the lengths in the following order: 1(62 times), 2(62 times) and so on.
-
The performance is quite good, since the same code will be repeated only after the integer overflow limit, which is quite large.
-
In this case also, the next code generated could be predicted by the use of some calculations.
Approach #3 Using hashcode[Accepted]
Algorithm
In this method, we make use of an inbuilt function to determine a code for mapping every URL. Again, the mapping is stored in a HashMap for decoding.
The hash code for a String object is computed(using int arithmetic) as −
, where s[i] is the ith character of the string, n is the length of the string.
Performance Analysis
-
The number of URLs that can be encoded is limited by the range of , since uses integer calculations.
-
The average length of the encoded URL isn't directly related to the incoming length.
-
The doesn't generate unique codes for different string. This property of getting the same code for two different inputs is called collision. Thus, as the number of encoded URLs increases, the probability of collisions increases, which leads to failure.
-
The following figure demonstrates the mapping of different objects to the same hashcode and the increasing probability of collisions with increasing number of objects.
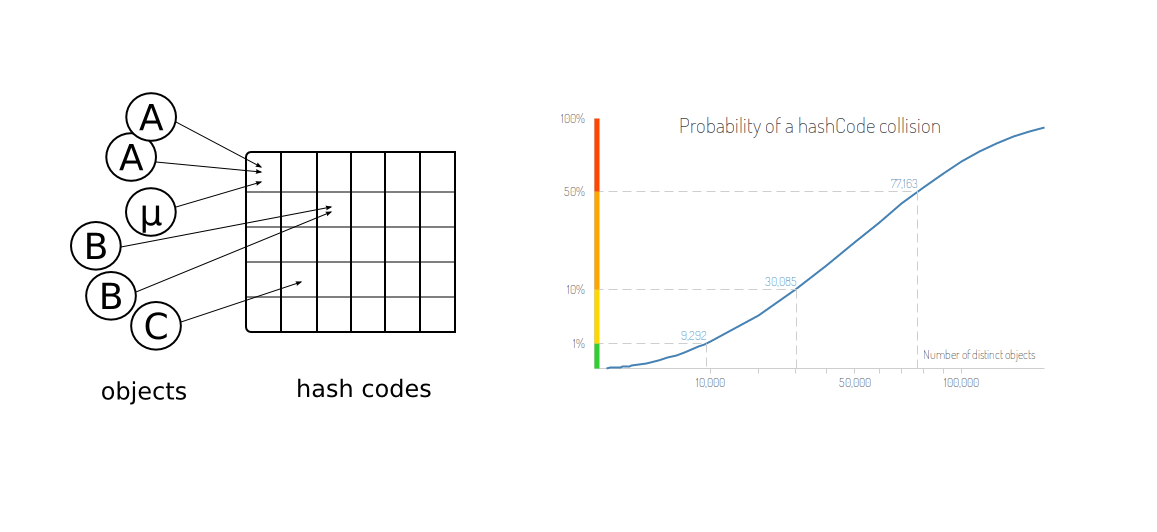
-
Thus, it isn't necessary that the collisions start occuring only after a certain number of strings have been encoded, but they could occur way before the limit is even near to the . This is similar to birthday paradox i.e. the probability of two people having the same birthday is nearly 50% if we consider only 23 people and 99.9% with just 70 people.
-
Predicting the encoded URL isn't easy in this scheme.
Approach #4 Using random number[Accepted]
Algorithm
In this case, we generate a random integer to be used as the code. In case the generated code happens to be already mapped to some previous , we generate a new random integer to be used as the code. The data is again stored in a HashMap to help in the decoding process.
Performance Analysis
-
The number of URLs that can be encoded is limited by the range of .
-
The average length of the codes generated is independent of the 's length, since a random integer is used.
-
The length of the URL isn't necessarily shorter than the incoming . It is only dependent on the relative order in which the URLs are encoded.
-
Since a random number is used for coding, again, as in the previous case, the number of collisions could increase with the increasing number of input strings, leading to performance degradation.
-
Determining the encoded URL isn't possible in this scheme, since we make use of random numbers.
Approach #5 Random fixed-length encoding[Accepted]
Algorithm
In this case, again, we make use of the set of numbers and alphabets to generate the coding for the given URLs, similar to Approach 2. But in this case, the length of the code is fixed to 6 only. Further, random characters from the string to form the characters of the code. In case, the code generated collides with some previously generated code, we form a new random code.
Performance Analysis
-
The number of URLs that can be encoded is quite large in this case, nearly of the order .
-
The length of the encoded URLs is fixed to 6 units, which is a significant reduction for very large URLs.
-
The performance of this scheme is quite good, due to a very less probability of repeated same codes generated.
-
We can increase the number of encodings possible as well, by increasing the length of the encoded strings. Thus, there exists a tradeoff between the length of the code and the number of encodings possible.
-
Predicting the encoding isn't possible in this scheme since random numbers are used.
Analysis written by: @vinod23