All leaked interview problems are collected from Internet.
616. Add Bold Tag in String
Given a string s and a list of strings dict, you need to add a closed pair of bold tag
<b> and </b> to wrap the substrings in s that exist in dict. If two such substrings overlap, you need to wrap them together by only one pair of closed bold tag. Also, if two substrings wrapped by bold tags are consecutive, you need to combine them.
Example 1:
Input: s = "abcxyz123" dict = ["abc","123"] Output: "<b>abc</b>xyz<b>123</b>"
Example 2:
Input: s = "aaabbcc" dict = ["aaa","aab","bc"] Output: "<b>aaabbc</b>c"
Note:
- The given dict won't contain duplicates, and its length won't exceed 100.
- All the strings in input have length in range [1, 1000].
Solution
Approach #1 Brute Force [Time Limit Exceeded]
Algorithm
In order to proceed with the solution to the given problem, the first basic step is to identify the substrings of the given string which exist in the given dictionary . For doing this, firstly, we add the given words in the dictionary to a . Then, we iterate over the given string and consider every possible substring of to check if it exists in the given dictionary . If so, we add the start and end index to a . Each element of takes the form: . Here, and represent the start and the end index of the substring which matches with any word in the dictionary.
By doing this, we are done with the first step. Now, the problem reduces mainly to identifying the sets of overlapping intervals from among the intervals present in the and adding the tags appropriately at those locations.
To do so, firstly, we sort the based on the start indices. In case of equality of start indices, we sort the elements based on their end indices. After this, we start creating our resultant string, . The substring of from the beginning till the first start index needs to be added as such to . Then, we pick up the first starting index from the . This index acts as the position to put the opening bold tag. In order to determine the end index(for placing the closing bold tag) by considering the merging required for consecutive or overlapping intervals, for the current range considered, we check if the start index of the next interval in lies before or at the index one larger than end of the current interval. If so, it indicates that either there is an overlap(if the next start index lies before or at the current end index), or the existence of consecutive intervals(if the next start index lies at the current end index + 1).
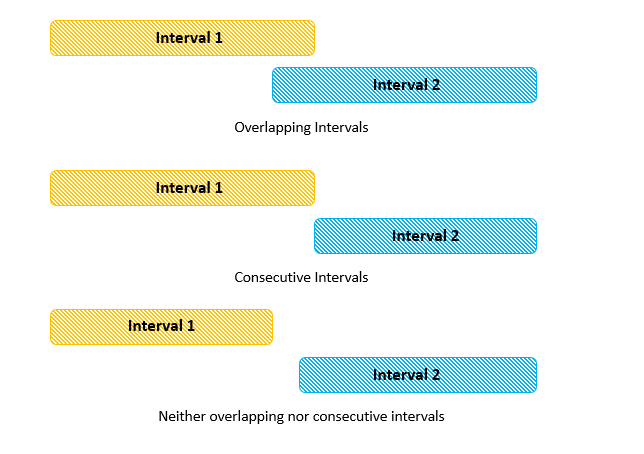
If any of these cases occur, we know that the next interval can be merged with the current one. Thus, we update the end index to point to the next interval's end index. We also update our current interval to the next interval and again check the overlapping or consecutive property of the new interval and its next one. We keep on updating the current interval till we reach an interval which doesn't satisfy any of these properties. The end index of the last interval found satisfying this property marks the position for the closing bold tag.
Since, we had reached the end of the overlapping/consecutive intervals, the substring lying beyond the end index found last and the start index existing beyond this end index in the doesn't exist in the dicitionary . Thus, we need to append this substring directly to the resultant string formed so far.
We keep on continuing this process till the whole range till the end index of the last interval has been exhausted. The substring left beyond this point is also appended directly to the formed till now.
Complexity Analysis
-
Time complexity : . Generating list of intervals will take , where represents string length.
-
Space complexity : . size grows upto and size will be equal to the size of . Here, refers to the size of .And size can grow upto in worst case, where refers to size.
Approach #2 Similar to Merge Interval Problem [Accepted]
In the last approach, to identify the substrings of which exist in the dictionary , we checked every possible substring of to see if it exists in this. Instead of doing the identification in this manner, we can be a bit smarter. We can pick up every word of the dictionary. For every word of the dictionary chosen currently, say of length , it is obvious that the substrings in only with length , can match with the . Thus, instead of blindly checking for 's match with every substring in , we check only the substrings with length . The matching substrings' indices are again added to the similar to the last approach.
The rest of the process remains the same as the last approach. The following animation illustrates the process for a clearer understanding.
!?!../Documents/616_Add_Bold_Tag_2.json:1000,563!?!
Complexity Analysis
-
Time complexity : . Generating list will take , where is the average string length of .
-
Space complexity : . size grows upto and size can grow upto in worst case.
Approach #3 Using Boolean(Marking) Array[Accepted]
This approach is inspired by @compton_scatter.
Another idea could be to merge the process of identification of the substrings in matching with the words in . To do so, we make use of an array for marking the positions of the substrings in which are present in . A True value at indicates that the current character is a part of the substring which is present in .
We identify the substrings in which are present in similar to the last approach, by considering only substrings of length for a dictionary word . Whenver such a substring is found with its beginning index as (and end index ), we mark all such positions in as True.
Thus, in this way, whenever a overlapping or consecutive matching substrings exist in , a continuous sequence of True values is present in . Keeping this idea in mind, we traverse over the string and keep on putting the current character in the resultant string . At every step, we also check if the array contains the beginning or end of a continuous sequence of True values. At the beginnning of such a sequence, we put an opening bold tag and then keep on putting the characters of till we find a position corresponding to which the last sequence of continuous True values breaks(the first False value is found). We put a closing bold tag at such a position. After this, we again keep on putting the characters of in till we find the next True value and we keep on continuing the process in the same manner.
The following animation illustrates the process for a better visualization of the process.
!?!../Documents/616_Add_Bold_Tag_3.json:1000,563!?!
Complexity Analysis
-
Time complexity : . Three nested loops are there to fill array.
-
Space complexity : . and size grows upto .
Analysis written by: @vinod23